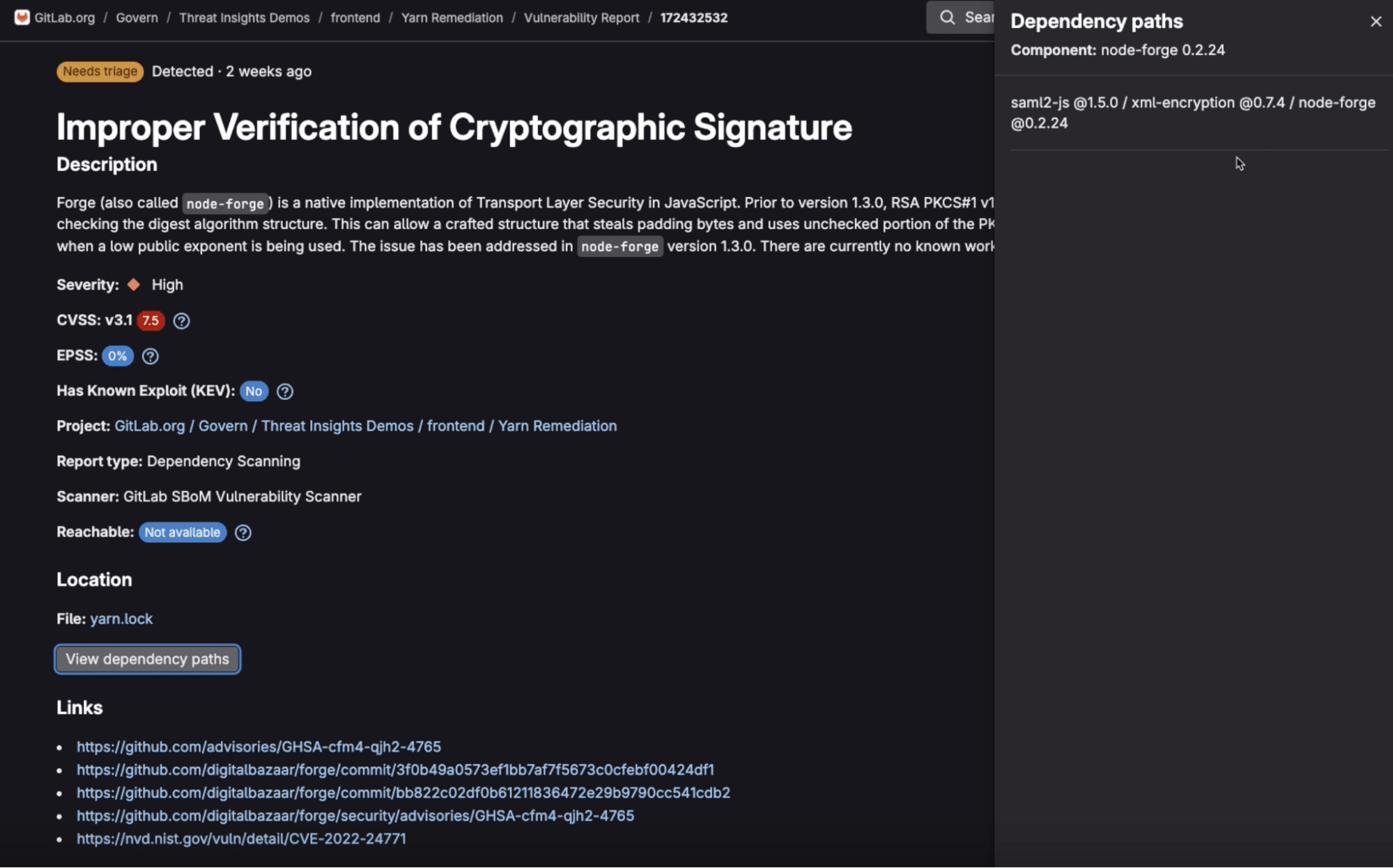
These observations emerge from our quarterly control monitoring process, where we systematically assess the effectiveness of security controls supporting our certifications (SOC 2, ISO 27001, etc.). Observations can also be the output of our external audits from third-party assessors. Observations aren't just compliance checkboxes, they represent real security risks that need prompt, visible remediation.
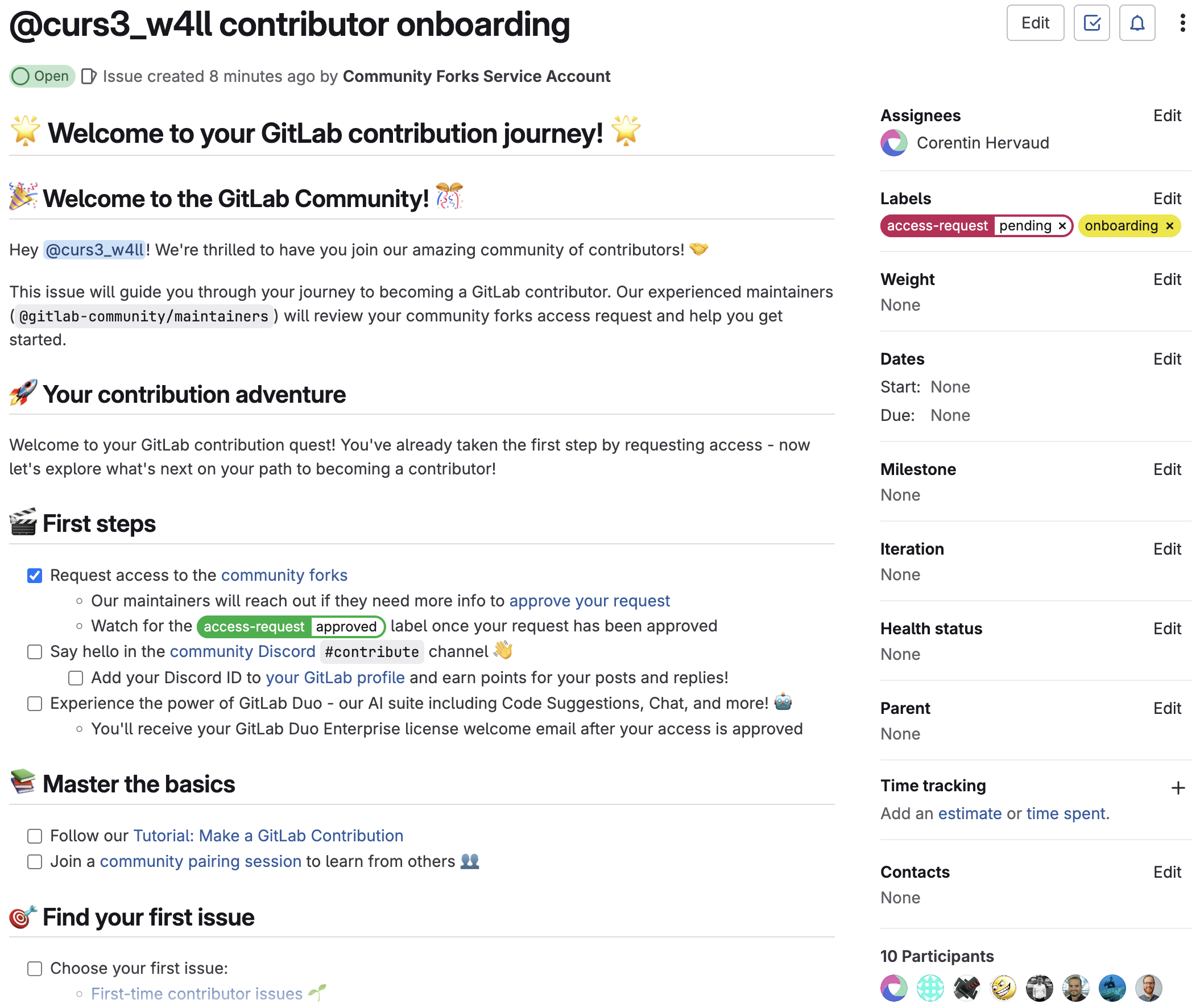
Observation management is the process by which we manage these observations from identification through remediation to closure. In this article, you'll learn how the GitLab Security Team uses the DevSecOps platform to manage and remediate observations, and the efficiencies we've realized from doing so.
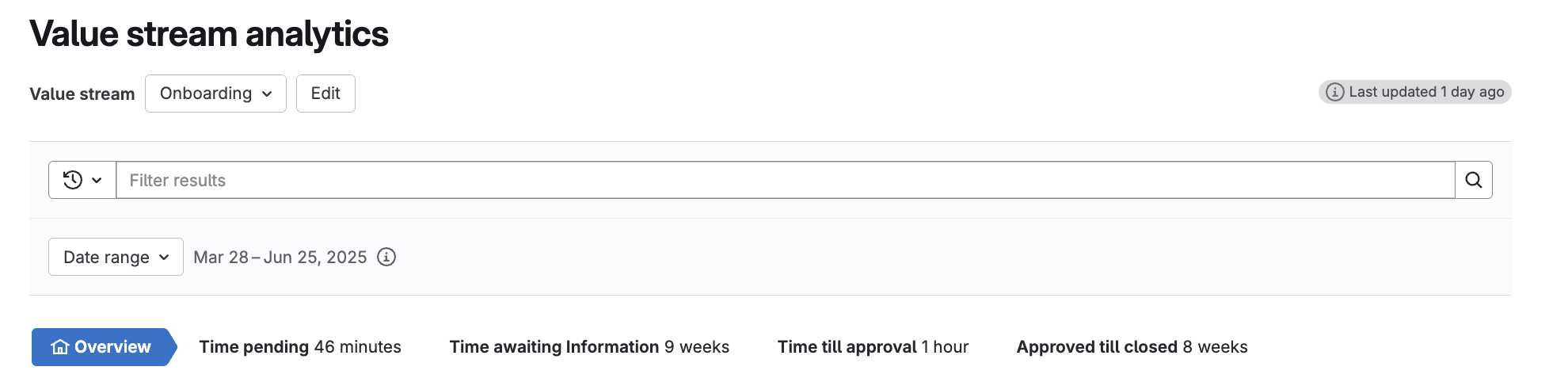
The GitLab observation lifecycle: From identification to resolution
The lifecycle of an observation encompasses the entire process from initial identification by compliance engineers through to completed remediation by remediation owners. This lifecycle enables real-time transparent status reporting and that is easier for all stakeholders to understand and follow.
Here are the stages of the observation lifecycle:
1. Identification
- Compliance engineers identify potential observations during quarterly monitoring.
- Initial validation occurs to confirm the finding represents a genuine control gap.
- Detailed documentation begins immediately in a GitLab issue.
- The root cause of the observation is determined and a remediation plan to address the root cause is established.
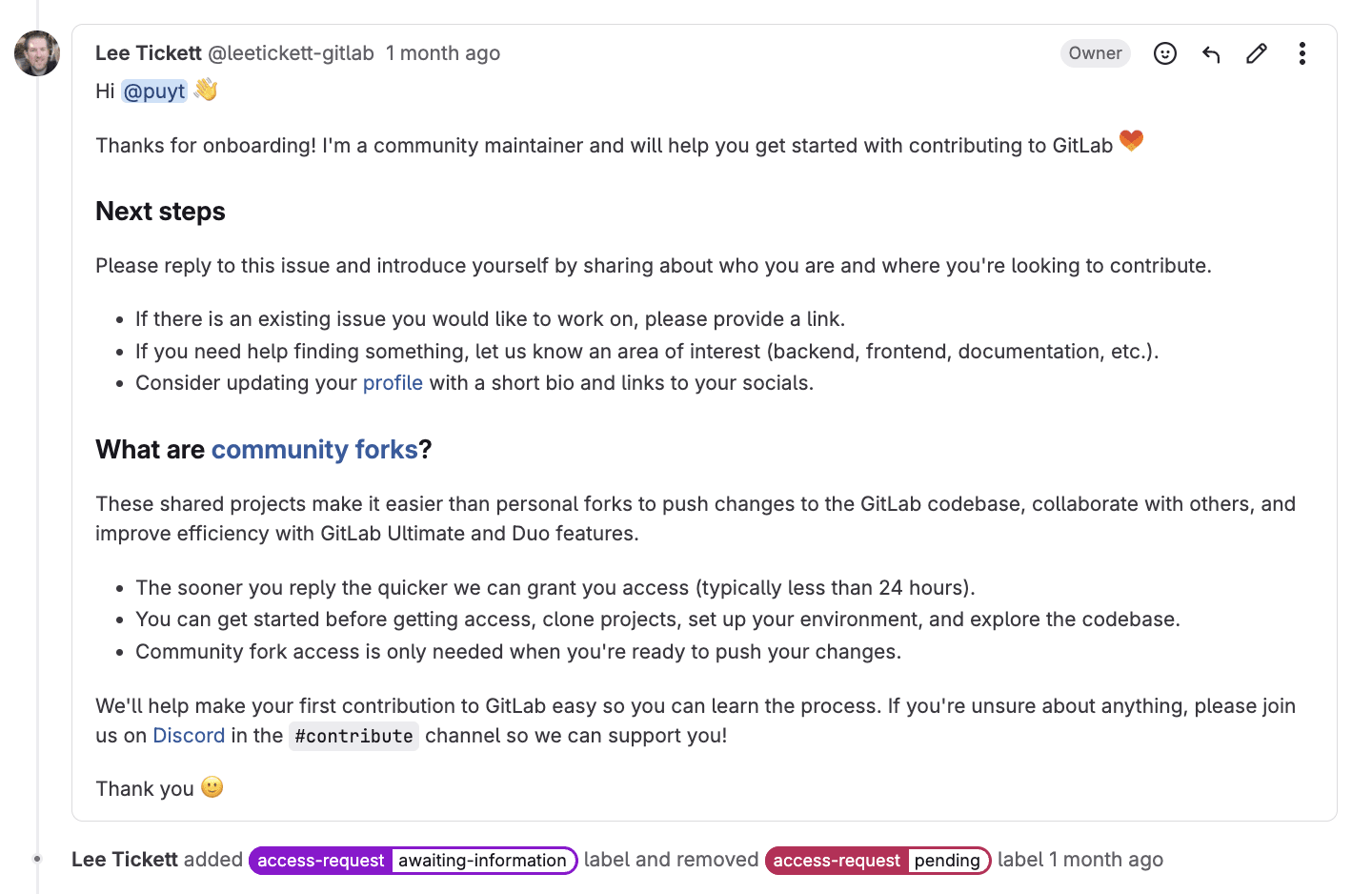
2. Validation
- Issue is assigned to the appropriate remediation owner (usually a team lead or department manager).
- Remediation owner reviews and confirms they understand and accept ownership.
- The remediation plan is reviewed, prioritized, and updated collaboratively as needed.
3. In-progress
- Active remediation work begins with clear milestones and deadlines.
- Regular updates are provided through GitLab comments and status changes.
- Collaboration happens transparently where all stakeholders can see progress.
4. Remediated
- Remediation owner marks work complete and provides evidence.
- Issue transitions to compliance review for validation.
5. Resolution
- Compliance engineer verifies exit criteria are met.
- The issue is closed with final documentation.
- Lessons learned are captured for future prevention.
Alternative paths handle blocked work, risk acceptance decisions, and stalled remediation efforts with appropriate escalation workflows.
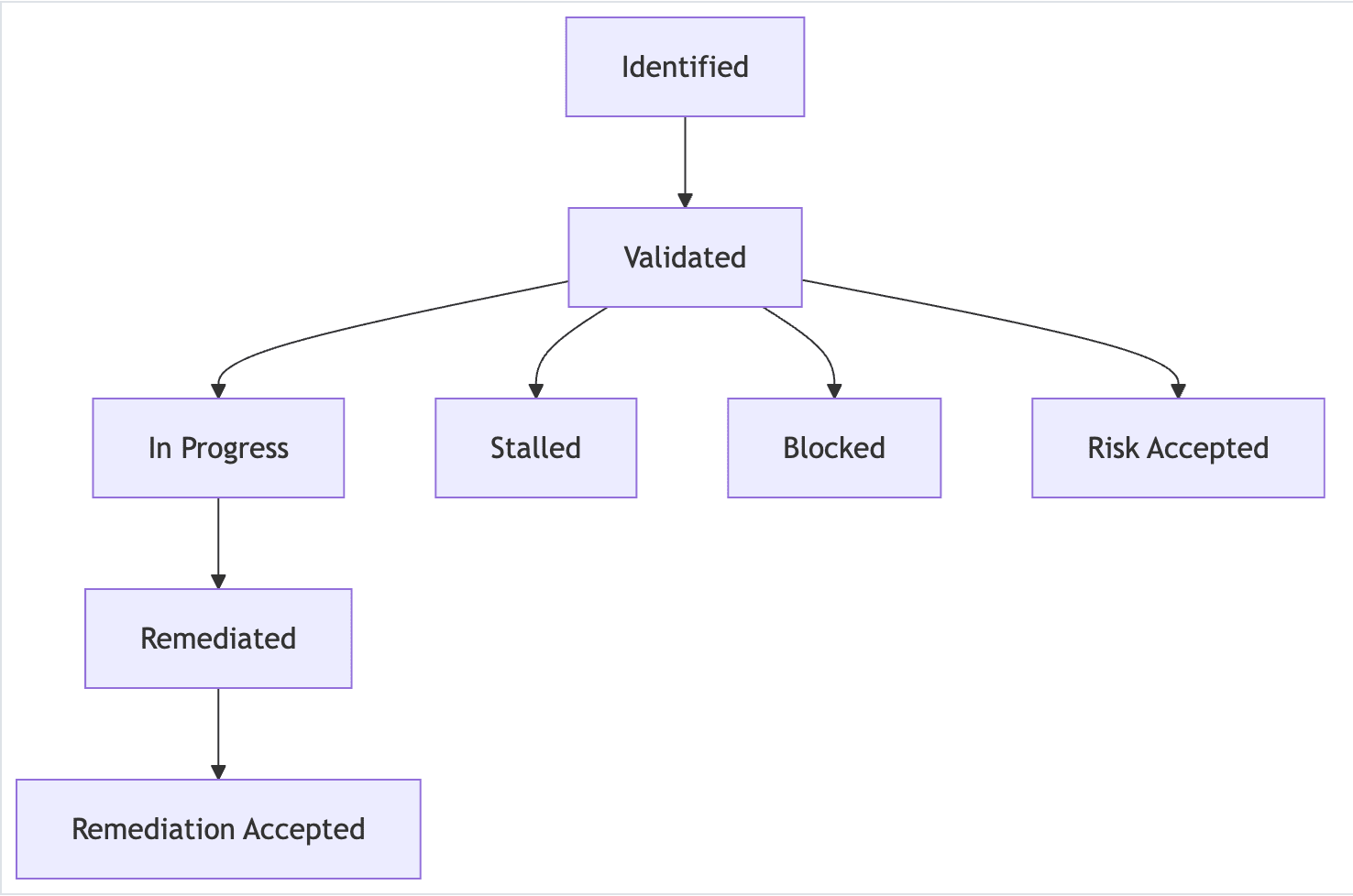 <center><i>Example of observation lifecycle</i></center>
<center><i>Example of observation lifecycle</i></center>
The power of transparency in GitLab
Effective observation management shouldn't require detective work to determine basic information like ownership, status, or priority. Yet most organizations find themselves exactly in this scenario: compliance teams chasing updates, operational teams unaware of their responsibilities, and leadership lacking visibility into real risk exposure until audit season arrives.
The Security Compliance team at GitLab faced these exact problems. Our team initially used a dedicated GRC tool as the single source of truth for outstanding observations, but the lack of visibility to key stakeholders meant minimal remediation actually occurred. The team found themselves spending their time on administrative work, rather than guiding remediation efforts.
Our solution was to move observation management directly into GitLab issues within a dedicated project. This approach transforms observations from compliance issues into visible, actionable work items that integrate naturally into development and operations workflows. Every stakeholder can see what needs attention, collaborate on remediation plans, and track progress in real time, creating the transparency and accountability that traditional tools simply can't deliver.
Smart organization through labels and issue boards
GitLab allows teams to categorize observation issues into multiple organizational views. The Security Compliance team uses the following to categorize observations:
- Workflow:
~workflow::identified,~workflow::validated,~workflow::in progress,~workflow::remediated - Department:
~dept::engineering,~dept::security,~dept::product - Risk Severity:
~risk::critical,~risk::high,~risk::medium,~risk::low - System:
~system::gitlab,~system::gcp,~system::hr-systems - Program:
~program::soc2,~program::iso,~program::fedramp,~program::pci
These labels are then leveraged to create issue boards:
- Workflow boards visualize the observation lifecycle stages.
- Department boards show each team's remediation workload.
- Risk-based boards prioritize critical findings requiring immediate attention.
- System boards visualize observations by system.
- Program boards track certification-specific observation resolution.
Labels enable powerful filtering and reporting while supporting automated workflows through our triage bot policies. Please refer to the automation section for more details on our automation strategy.
Automation: Working smarter, not harder
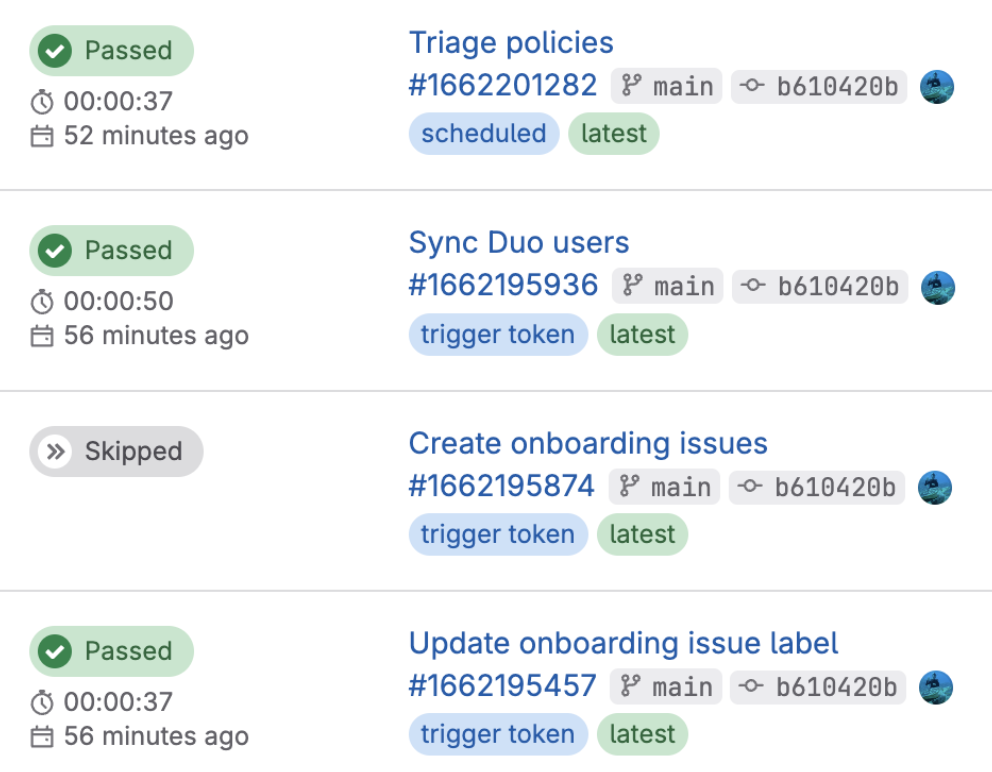
Managing dozens of observations across multiple certifications requires smart automation. The Security Compliance team utilizes the triage bot, which is an open source project hosted in GitLab. The triage bot gem aims to enable project managers to automatically triage issues in GitLab projects or groups based on defined policies. This helps manage issue hygiene so stakeholders can focus their efforts on remediation.
Within the observation management project, we have policies written to ensure there is an assignee on each issue, each issue has required labels, issues are updated every 30 days, and blocked and stalled issues are nudged every 90 days. In addition, a weekly summary issue is created to summarize all the issues out of compliance based on our defined policies. This enables team members to monitor issues efficiently and spend less time on administrative tasks.
Measuring success: Key metrics and reporting
GitLab's raw issue data can be leveraged into actionable intelligence. Organizations can extract meaningful insights from issue creation date, closed date, last updated date, and labels. The following metrics provide a comprehensive view of your observation management effectiveness:
Resolution Efficiency Analysis: Average time from identification to resolution by department and severity
Track issue creation versus close dates across departments and severity levels to identify bottlenecks and measure performance against SLAs. This reveals which teams excel at rapid response and which may need additional resources or process improvements.
Real-Time Risk Assessment: Current risk profile based on open critical and high risk observations
Leverage risk level labels to create dynamic visualizations of your organization's current risk exposure. This provides leadership with an immediate understanding of critical observations requiring urgent attention.
Strategic Resource Allocation: Department-level risk distribution for targeted improvement efforts
Identify which departments are responsible for remediation of the highest-risk observations to prioritize resources, oversight, and projects. This data-driven approach ensures improvement efforts focus where they'll have maximum impact.
Compliance Readiness Monitoring: Certification-specific observation counts and resolution rates
Utilize certification labels to assess audit preparedness and track progress toward compliance goals. This metric provides early warning of potential certification risks and validates remediation efforts.
Accountability Tracking: Overdue remediations
Monitor SLA compliance to ensure observations receive timely attention. This metric highlights systemic delays and enables proactive intervention before minor issues become major problems.
Engagement Health Check: Observation freshness
Track recent activity (updates within 30 days) to ensure observations remain actively managed rather than forgotten. This metric identifies stagnant issues that may require escalation or reassignment.
Advanced strategies: Taking observation management further
Here's what you can do to deepen the impact of observation management in your organization.
Integrate with security tools
Modern observation management extends beyond manual tracking by connecting with your existing security infrastructure. Organizations can configure vulnerability scanners and security monitoring tools to automatically generate observation issues, eliminating manual data entry and ensuring comprehensive coverage.
Apply predictive analytics
Historical observation data becomes a powerful forecasting tool when properly analyzed. Organizations can leverage past remediation patterns to predict future timelines and resource requirements, enabling more accurate project planning and budget allocation. Pattern recognition in observation types reveals systemic vulnerabilities that warrant preventive controls, shifting focus from reactive to proactive risk management. Advanced implementations incorporate multiple data sources into sophisticated risk scoring algorithms that provide nuanced threat assessments and priority rankings.
Customize for stakeholders
Effective observation management recognizes that different roles require different perspectives on the same data. Role-based dashboards deliver tailored views for executives seeking high-level risk summaries, department managers tracking team performance, and individual contributors managing their assigned observations. Automated reporting systems can be configured to match various audience needs and communication preferences, from detailed technical reports to executive briefings. Self-service analytics capabilities empower stakeholders to conduct ad-hoc analysis and generate custom insights without requiring technical expertise or support.
Move from mere compliance to operational excellence
GitLab's approach to observation management represents more than a tool change, it's a fundamental shift from reactive compliance to proactive risk mitigation. By breaking down silos between compliance teams and operational stakeholders, organizations achieve unprecedented visibility while dramatically improving remediation outcomes.
The results are measurable: faster resolution through transparent accountability, active stakeholder collaboration instead of reluctant participation, and continuous audit readiness rather than periodic scrambles. Automated workflows free compliance professionals for strategic work while rich data enables predictive analytics that shift focus from reactive firefighting to proactive prevention.
Most importantly, this approach elevates compliance from burden to strategic enabler. When observations become visible, trackable work items integrated into operational workflows, organizations develop stronger security culture and lasting improvements that extend beyond any single audit cycle. The outcome isn't just regulatory compliance. It's organizational resilience and competitive advantage through superior risk management.
]]>Want to learn more about GitLab's security compliance practices? Check out our Security Compliance Handbook for additional insights and implementation guidance.

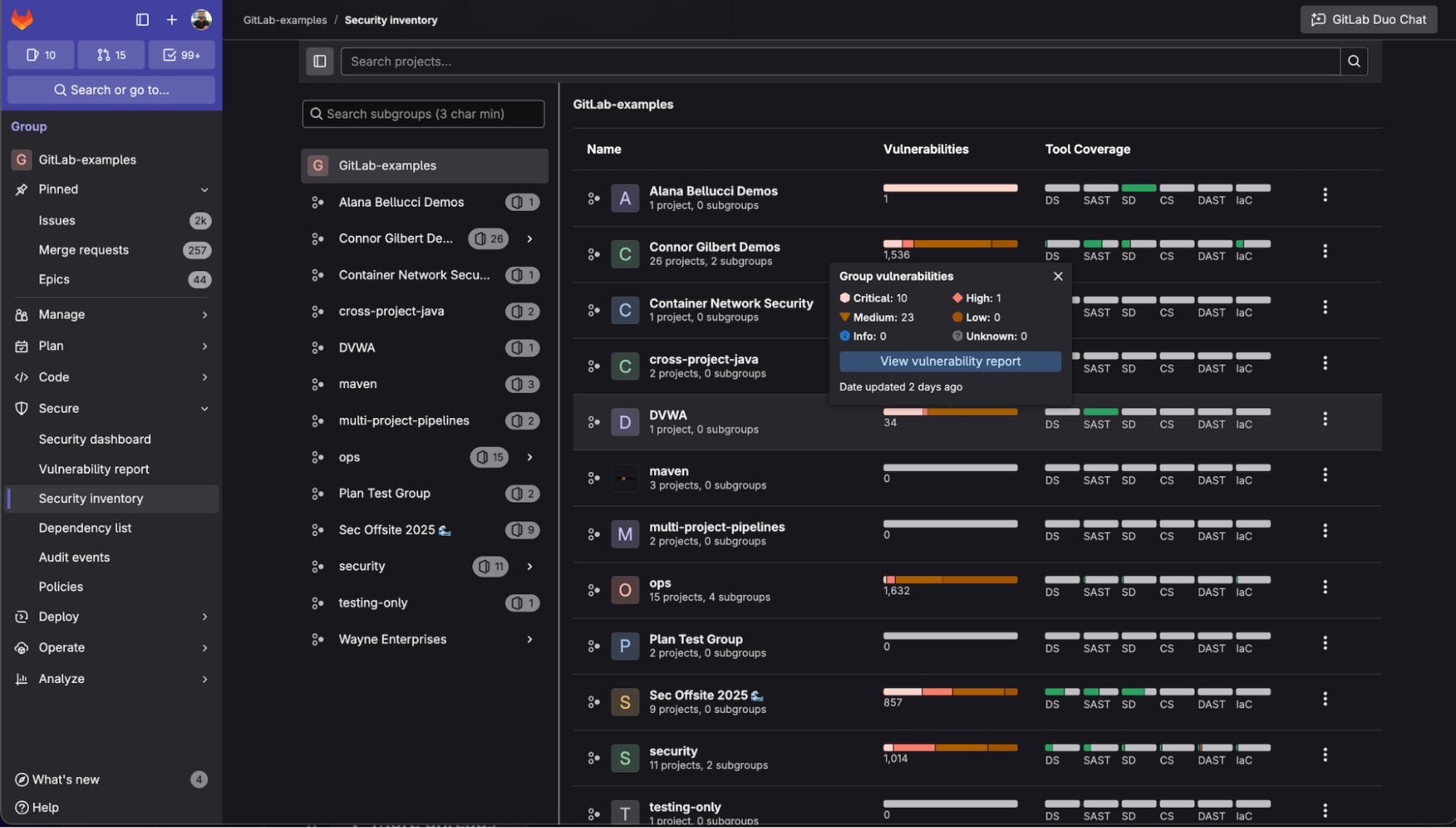 Learn more by watching Security Inventory in action:
<!-- blank line --> <figure class="video_container"> <iframe src="https://www.youtube.com/embed/yqo6aJLS9Fw?si=CtYmsF-PLN1UKt83" frameborder="0" allowfullscreen="true"> </iframe> </figure> <!-- blank line -->
Learn more by watching Security Inventory in action:
<!-- blank line --> <figure class="video_container"> <iframe src="https://www.youtube.com/embed/yqo6aJLS9Fw?si=CtYmsF-PLN1UKt83" frameborder="0" allowfullscreen="true"> </iframe> </figure> <!-- blank line -->